Built for engineers and agents
AI-native feature flags + dynamic config
Designed for safe launches and automatic rollbacks.
Designed for safe launches and automatic rollbacks.
Built for speed and safety
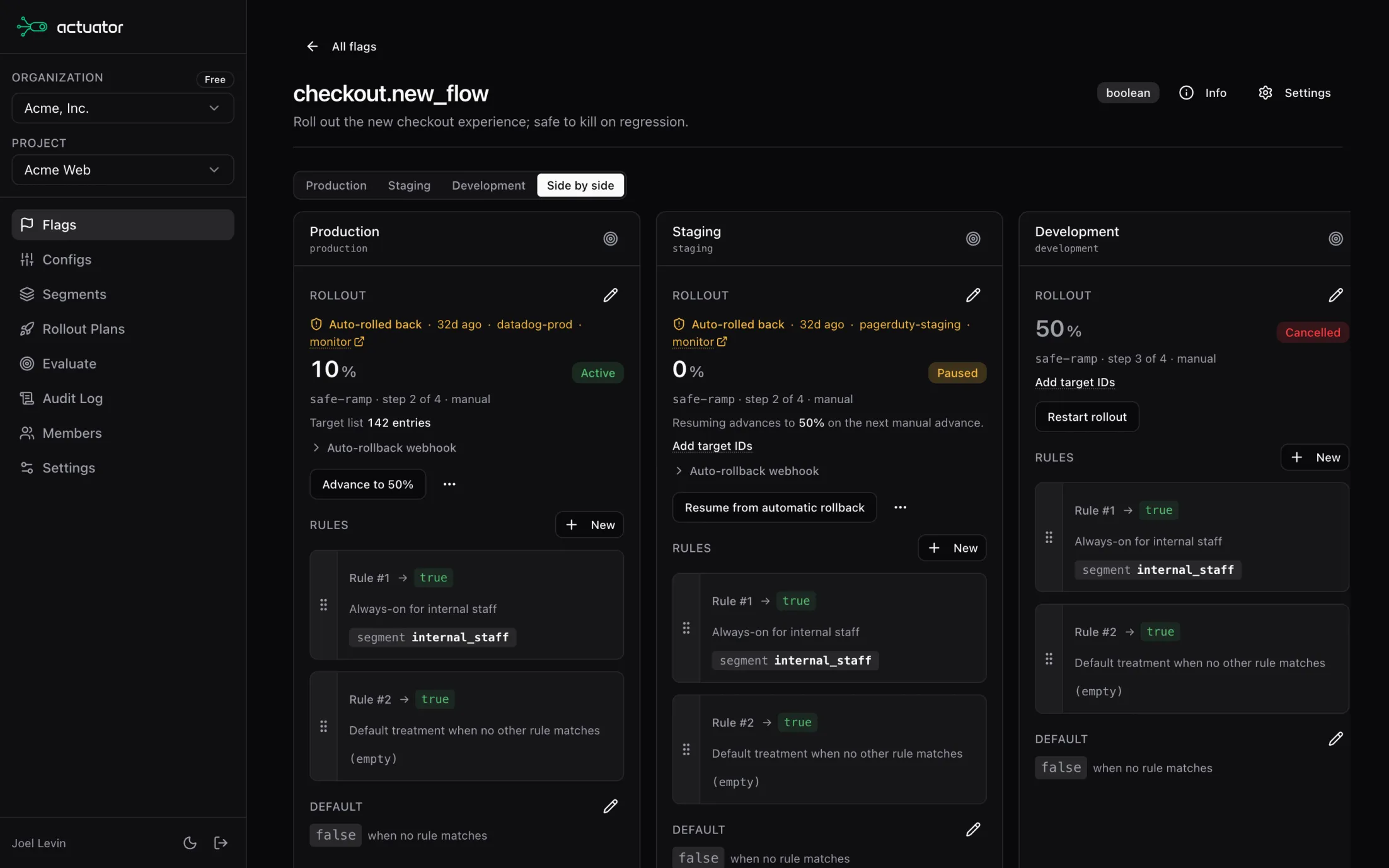
Agents roll out, automatic rollbacks protect your customers.
Rollout and ramp on pre-configured schedules. Automatically avoid changes on weekends, nights, and even during the big demo.
Wire a metric to a rollout and automatically roll back if anything goes wrong.
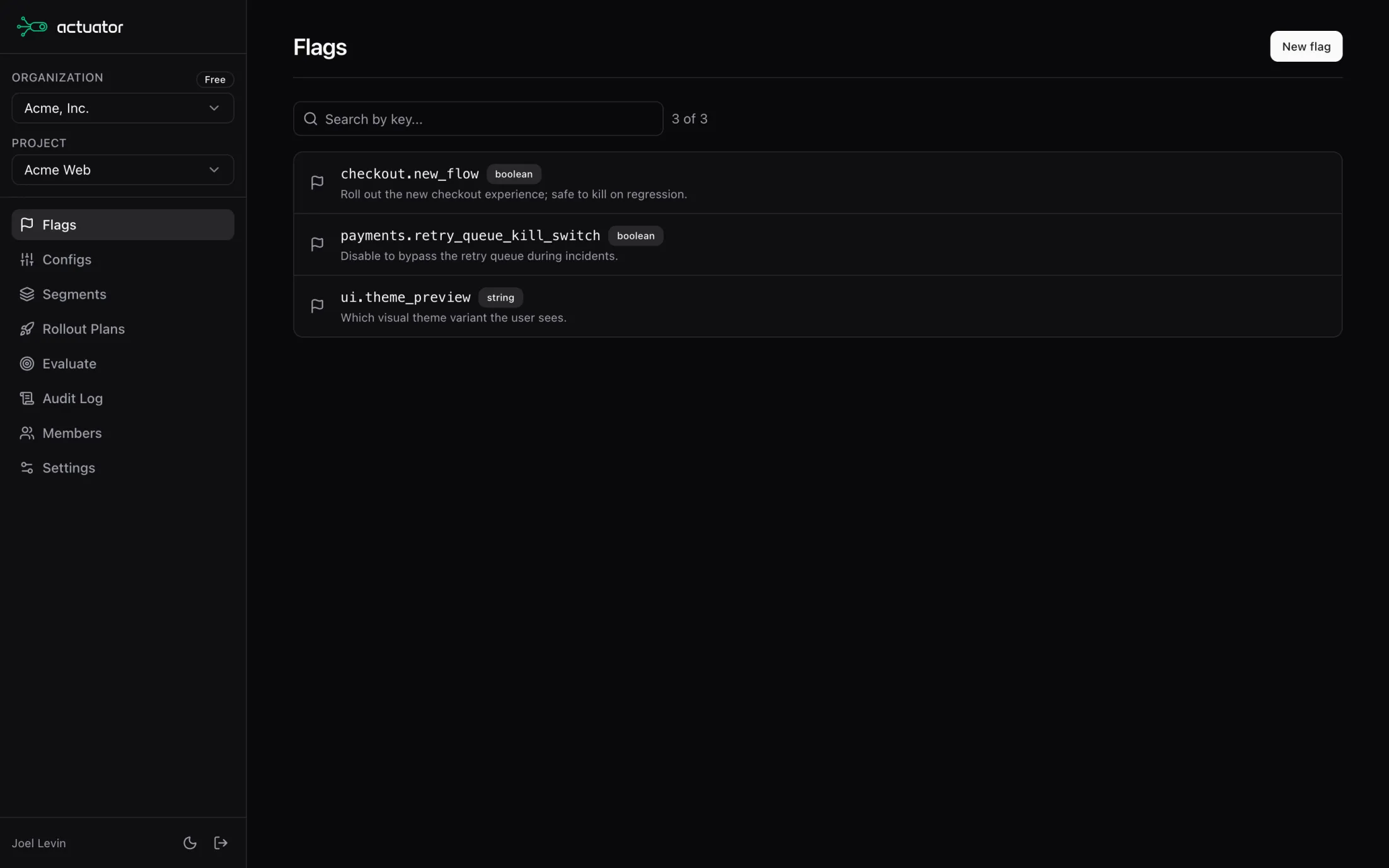
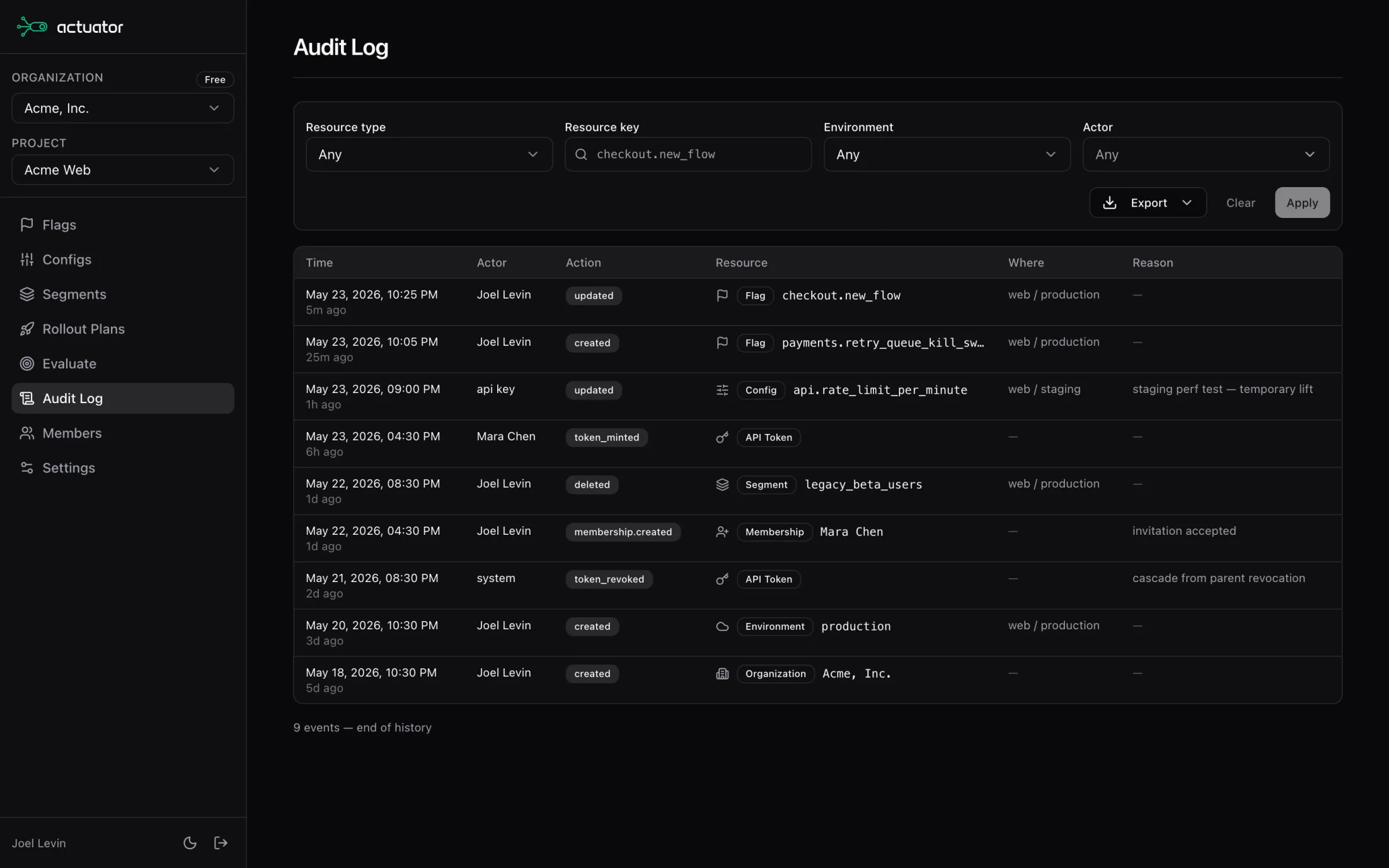
Let agents manage flags, configs, and rollouts. Every change lands in the audit log.
See it
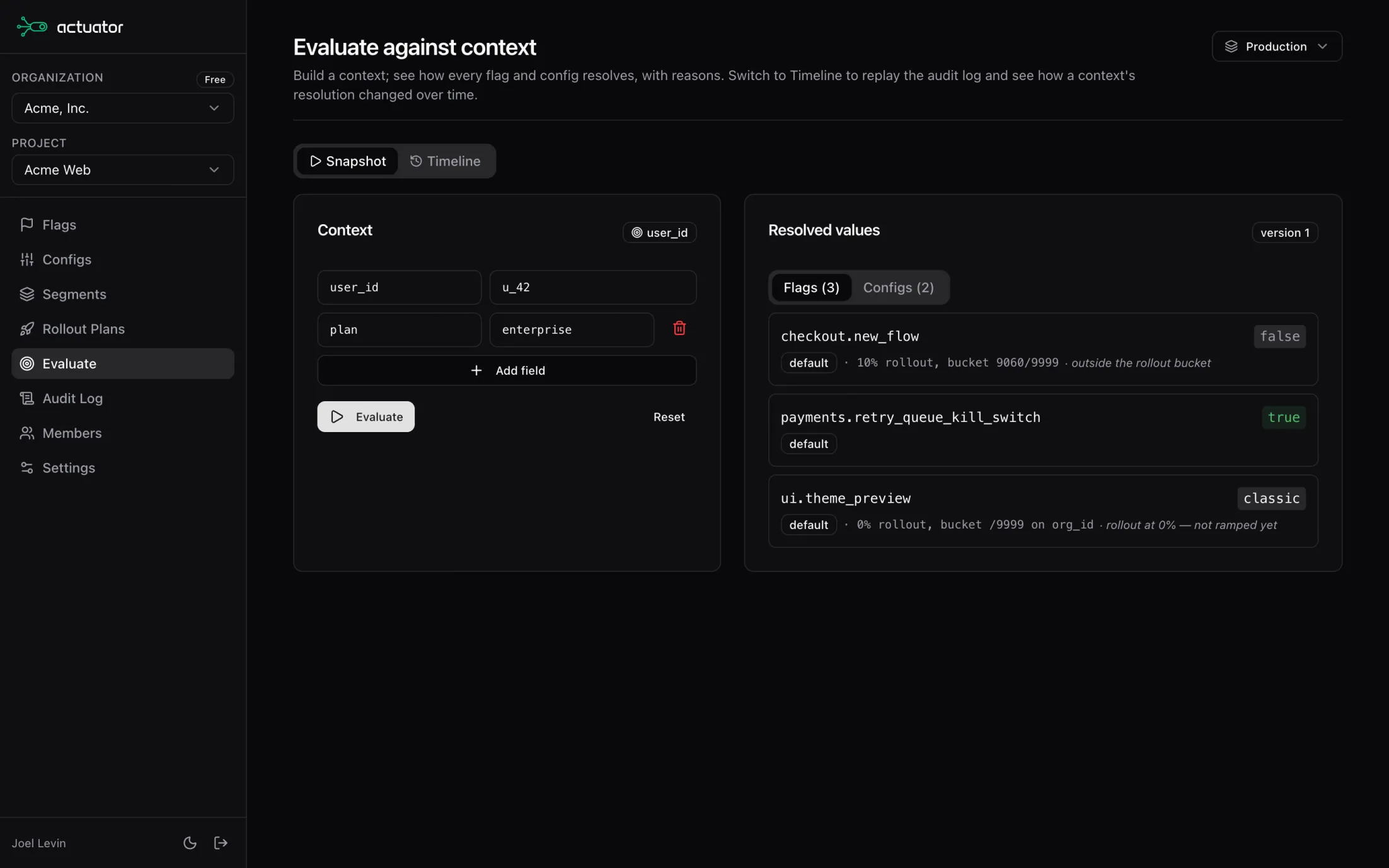
Every evaluation includes a structured reason: which operator fired, which field matched, what the actual and expected values were, and any notes the evaluator wants to surface. Type mismatches, missing fields, and segment cycles all show up in the reason instead of getting swallowed. Pass verboseReason=true for the full predicate tree.
{
"environmentId": "0c7e3b0a-9f1c-4e22-8d7b-...",
"context": { "userId": "u_42", "country": "CA" },
"version": 42,
"asOf": "2026-05-01T21:47:18Z",
"evaluations": {
"new-checkout-flow": {
"value": true,
"defaultValue": false,
"reason": {
"kind": "rule_match",
"ruleIndex": 2,
"detail": {
"operator": "$segment",
"segment": "is_beta_user"
},
"notes": []
},
"decisionHash": "sha256:7f3a8d..."
}
}
}{
"environmentId": "0c7e3b0a-9f1c-4e22-8d7b-...",
"context": { "userId": "u_42", "country": "CA" },
"version": 42,
"asOf": "2026-05-01T21:47:18Z",
"evaluations": {
"new-checkout-flow": {
"value": true,
"defaultValue": false,
"reason": {
"kind": "rule_match",
"ruleIndex": 2,
"detail": {
"operator": "$segment",
"segment": "is_beta_user"
},
"notes": [],
"trace": {
"operator": "$or",
"matchedBranchIndex": 1,
"branches": [
{ "operator": "$eq", "field": "country",
"expected": "US", "actual": "CA",
"matched": false },
{ "operator": "$segment",
"segment": "is_beta_user",
"matched": true }
]
}
},
"decisionHash": "sha256:7f3a8d..."
}
}
}AI-native capabilities
Capabilities tuned for agent-driven flag operations: propose, preview, verify, replay, audit, reason.
Agents connect via Model Context Protocol (MCP) and work at the operator's level of intent: proposing changes, evaluating for a context, querying the audit log.
Learn morePass a proposed ruleset and preview the exact changes before you commit.
Learn moreAgent change proposals: stage a change, preview the difference, and approve or deny to proceed. No unintended production changes.
Learn moreReplay the audit log against one context. "What did this user see between Tuesday and Friday, and which rule flipped them?" comes back as a timeline of values and reasons, per flag and config.
Learn morePass any past timestamp and Actuator reconstructs the ruleset from the audit log and evaluates against it.
Learn moreFull reasoning traces include every operator that fired and every branch that short-circuited.
Learn moreHow we compare
Most flag systems ship flags, segments, and an MCP server. Actuator differs by exposing full reasoning traces, replaying evaluations at any past timestamp, and previewing changes against live traffic before saving. We don't do experimentation; if you need a stats engine, Statsig or PostHog are the picks.
| Capability | Actuator | LaunchDarkly | Statsig | Unleash OSS | PostHog |
|---|---|---|---|---|---|
| Full reasoning trace | ✓ verboseReason: true | leaf summary | leaf summary | — | leaf summary |
| Time-travel evaluation | ✓ audit-log replay | audit log only | audit log only | audit log only | audit log only |
| Counterfactual preview | ✓ hypothetical ruleset | — | — | — | — |
| Flags + typed configs, one evaluator | ✓ one /evaluate | flags only | separate SDK methods | flags + variants | remote-config flag type |
| Save-time grammar enforcement | ✓ cycles, regex, types | direct cycles only | undocumented | n/a (flat segments) | undocumented |
| Published evaluator specification | ✓ EVALUATOR.md | SDK harness only | per-SDK internal | JSON test cases | none published |
| Experimentation / stats | — not our lane | ✓ | ✓ deep | — bring your own | ✓ |
Competitor capabilities reflect public docs as of April 2026. All five products ship flags, segment-style targeting, and an MCP server — those are baseline, not differentiators. Email us if we got something wrong and we'll fix the table.
Quickstart
Sign up, create an environment, mint a token. Evaluate flags and configs with a structured reason on every call.
# Evaluate a flag with a structured reason on every call:
curl -X POST https://useactuator.ai/api/v1/envs/$ENV/evaluate \
-H "Authorization: Bearer $TOKEN" \
-d '{
"context": { "user_id": "u_42", "country": "CA" },
"keys": ["new-checkout-flow"]
}'
# Add "verboseReason": true for the full predicate-tree trace,
# or "asOf": "<ISO 8601>" to evaluate against any past ruleset.Pricing
Unlimited evaluations on every tier — pricing scales with your team and surfaces, not your traffic. Free forever for evaluation and indie use; paid tiers start at $9.
Evaluate Actuator end-to-end. Real flags, real dashboard, real SDKs — no card, no time limit.
Side projects and small teams that have outgrown Free's caps. Real headroom for the price of a coffee.
Production teams running Actuator at real volume. Email support included.
Larger teams and security-conscious orgs. SSO, priority support, and 1-year audit retention.
Every plan includes unlimited evaluations, every primitive type (flags, configs, segments), audit log with CSV and NDJSON export, counterfactual preview, time-travel, and the MCP server. Team size, primitive count, retention window, and projects are what scale across tiers. Need something more — custom retention, dedicated infra, an SLA? Email hello@useactuator.ai.